
sonnet 5 shipped. your call where it runs.
anthropic just shipped sonnet 5. if your agents run on a server you own, under your own claude subscription, it’s already available to every one of them. nothing you’re running had to change, and you didn’t pay a cent extra to get the option.
that’s the whole point of running agents on hardware you control, signed into your own plan. new models show up in the plan you already have. you decide what to do with them.
what actually happened
sonnet 5 (claude-sonnet-5) is now generally available, and as of v2.1.197 it’s the default model in anthropic’s coding cli.
new model, new options. the question every team actually has is the boring one. do i need to do anything?
if your agents run on your own subscription, no
your agents run the official cli on a server you own, signed into your own claude account. the models come with that plan. we don’t host them, we don’t resell them, we don’t meter them back to you.
so sonnet 5 didn’t land as a migration. it landed as a new option sitting inside a plan you already pay for. no redeploy. no “please update your integration.” no waiting on a platform to flip it on for you, because there’s no platform in the middle. it was there for your agents the second it shipped.
the part that actually matters: you choose
newest isn’t automatically best for your job.
the early read from people running agents all day: sonnet 5 is fast, and for heavy multi-step work a lot of power users are staying on opus 4.8. and you don’t have to take that on vibes. here’s anthropic’s own numbers.
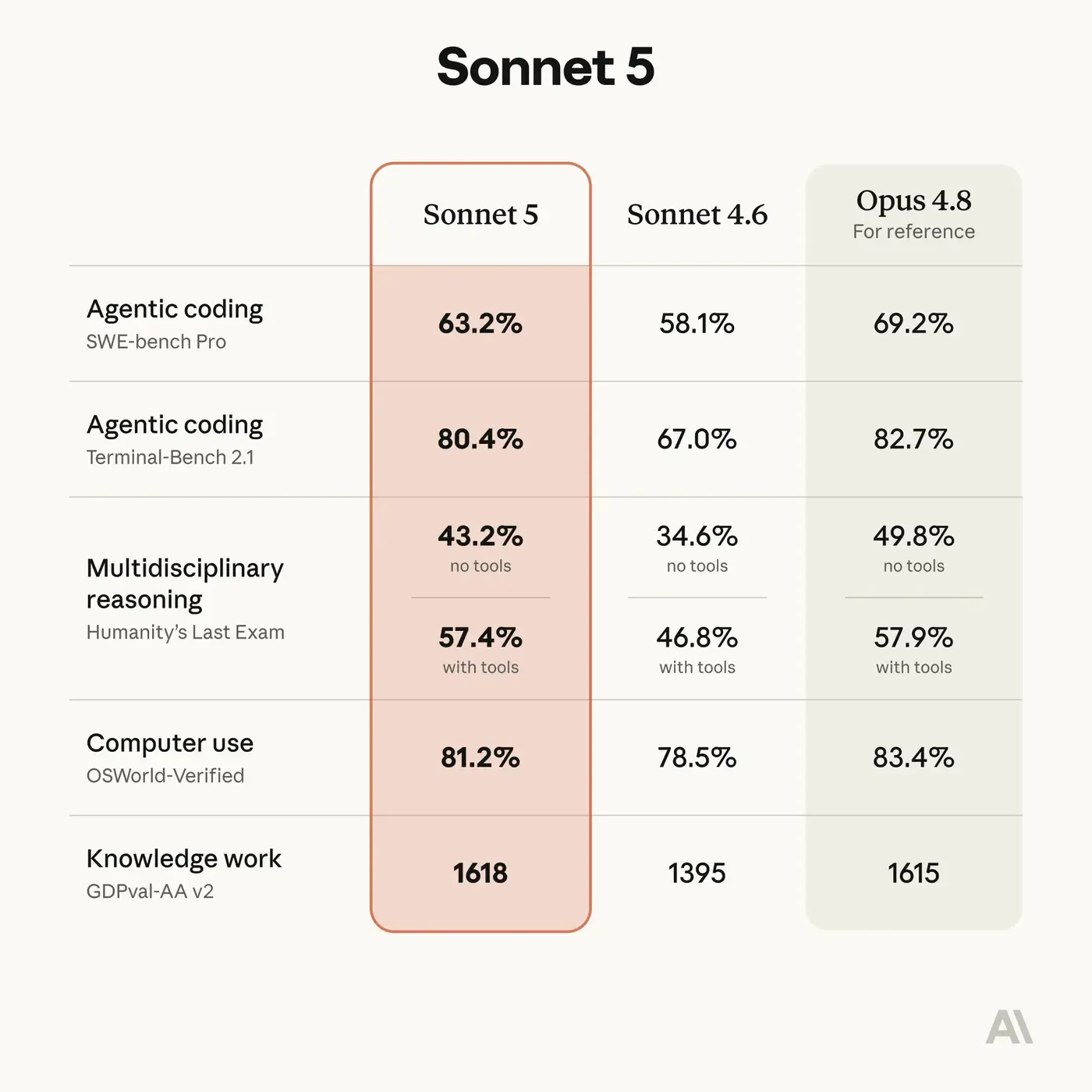
opus 4.8 still tops the heavy agentic coding and reasoning rows. sonnet 5 lands right behind and edges ahead on knowledge work. close race, different winners depending on the job.
then there’s how hard you have to push each one to get there.
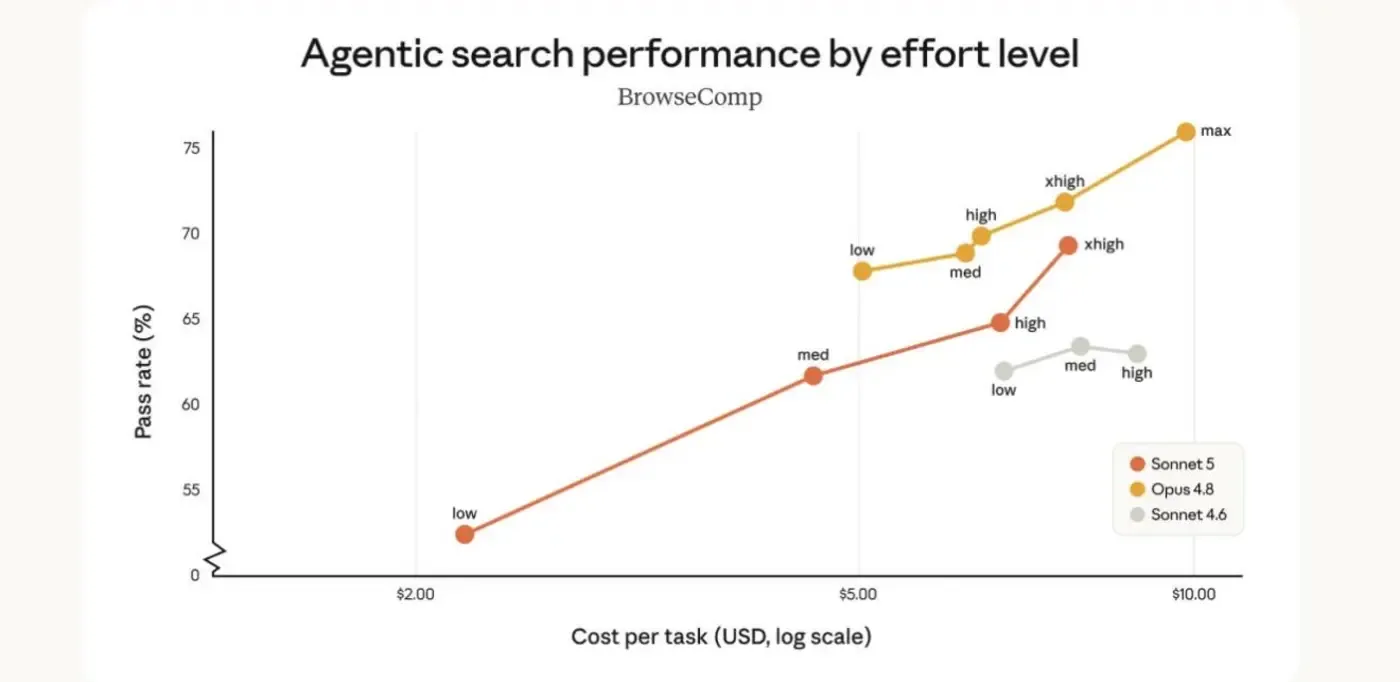
opus keeps climbing the harder you push it. sonnet 5 gets most of the way there at a lower effort level. so the real question was never “which model is best.” it’s “which model is right for this agent, on this task.”
on your own box you don’t pick a side. you pin the model per agent. your ci watcher runs one thing, your big refactor agent runs another, and the day a new model clearly wins a workload, you point that agent at it. one line. that’s the whole migration.
for the record, that’s exactly how we run our own fleet. 5dive ships with opus 4.8 as the default, because it leads the heavy agentic work our agents do all day. a few already run sonnet 5 where it wins. same box, same subscription, a different model per agent, each one chosen on purpose. sonnet 5 going GA didn’t force a single switch we didn’t ask for. that’s the feature.
the middleman is the tax
everyone ships fast now. normally that’s fine, until you’re renting model access through a platform that sits between you and every release. then they decide when you get the new model, and they get to wrap it in whatever they want.
when the box is yours and the subscription is yours, that middle layer is just gone. new models land in the plan you already pay for. you keep your setup. you keep choosing.
one thing to do today
if your agents run somewhere a vendor owns the model choice, ask them one question. when a better model ships, who decides when i get it, and can i run it side by side with what i’ve already got?
if the answer isn’t “you, the second it’s out,” you’re renting the wrong layer.
your agents should run on your box, on your subscription, on the models you pick. spin up a team at 5dive.ai.